

Fine tuning 이란?
pre-trained 모델을 새로운 Task에 적용시키는 과정을 말한다.
그 과정은 아래와 같이 분류할 수있다.
1. 새 데이터를 통해 모델 파라미터를 업데이트
2. 새 Task에 맞게 모델 구조 변형
이 글과 읽으면 좋은 글
이번 포스팅에서는 Fine Tuning(미세조정)을 효과적으로 할 수 있는 아이디어를 제시하고자 한다.

크게 4가지 케이스로 분류 가능하다.
1) 새 데이터셋이 클 경우
(1) pretrained 데이터와 유사성이 크다.

가장 좋은 상황으로 모든 옵션이 가능하다.
[ic]feature extractor[/ic] 뒷부분과 [ic]classifier[/ic]를 학습하길 추천한다.
(나머지는 freeze)
why?
- [ic]feature extractor[/ic] 가장 뒷부분이 해당 이미지의 특징을 가장 많이 가지고 있기 때문이다.
- 기존데이터와 비슷하기 때문에 전체 레이어를 학습시키는 건 비효율적이다.
(2) pretrained 데이터와 유사성이 작다.
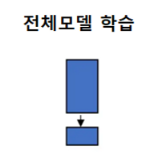
모델 전체를 학습할 것을 추천한다.
why?
- 데이터셋 크기가 크기 때문에 오버 피팅 가능성이 낮다.
- 기 학습된 weights 데이터 자체도 유용하게 사용가능하다.
2) 새 데이터셋이 작을 경우(1000장 이하)
(1) pretrained 데이터와 유사성이 크다.

[ic]classifier[/ic]만 학습하고 [ic]feature extractor[/ic] 부분은 freeze 한다.
why?
복잡한 모델일수록 input 데이터의 작은 특징을 다 잡아낸다. 문제는 데이터양이 small 하다는 거다.
학습한 데이터의 feature가 모든 데이터의 feature를 대변한다고 모델은 착각한다.
즉, 오버피팅이 발생된다.
(2) pretrained 데이터와 유사성이 작다.
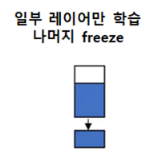
데이터가 small 한데 유사성까지 없다.
아주 최악의 상황이라 할 수 있다.
[ic]feature extractor[/ic]중 일부 layer를 학습시키고 나머지는 freeze 해야 한다.
문제는 이 균형을 찾기가 상당히 어렵다.
학습시키는 layer가 많아지면 바로 오버피팅에 빠질 것이고, 적어지면 전혀 학습을 못할 테니 말이다.
이때는 [ic]data augmentation[/ic] 기법을 통해 데이터 늘릴 방법을 모색해야 한다.
'머신러닝,딥러닝 > 딥러닝' 카테고리의 다른 글
| [pytorch] 모델 save/load 하는 방법 (0) | 2022.12.29 |
|---|---|
| [pytorch] Subset 사용법 정리 (0) | 2022.12.29 |
| [pytorch] pretrained model 쉽게 사용하는 방법 (0) | 2022.12.26 |
| [pytorch] nn.Dropout inplace 역할은 무엇일까? (0) | 2022.12.23 |
| [pytorch] model.eval() vs torch.no_grad() 차이 (1) | 2022.12.21 |



댓글